목차
- 디스크 접근 시간, 왜 중요할까요?
- HDD 성능을 좌우하는 두 가지 핵심 시간
- 탐색 시간(Seek Time): 헤드의 움직임
- 회전 지연 시간(Rotational Latency): 플래터의 회전
- 랜덤 액세스(Random Access): 느린 이유 파헤치기
- 순차 액세스(Sequential Access): 압도적으로 빠른 비결!
- 데이터 엔지니어 관점에서 본 디스크 접근 시간 최적화
- 데이터 배치 최적화: 파티셔닝과 클러스터링
- 컬럼 기반 파일 포맷 선택: Parquet, ORC
- 스트리밍 처리 고려: Kafka, Flink, Spark Streaming
- SSD의 등장과 디스크 접근 시간의 변화
- 백엔드 개발자를 위한 핵심: 디스크 접근 시간, 이것만 기억하세요!
디스크 접근 시간, 왜 중요할까요?
우리가 만드는 백엔드 애플리케이션이나 데이터 엔지니어링 시스템은 수많은 데이터를 디스크에 저장하고, 다시 읽어와서 처리합니다. 이때 데이터를 디스크에서 읽거나 쓰는 데 걸리는 시간을 디스크 접근 시간이라고 해요. 이 시간이 길어질수록 애플리케이션의 응답 속도는 느려지고, 전체 시스템의 성능은 저하됩니다.
특히 하드 디스크(HDD)는 물리적인 움직임이 수반되기 때문에, 데이터 접근 방식에 따라 성능 차이가 크게 발생합니다. 이를 이해하는 것은 효율적인 백엔드 시스템을 설계하고 데이터 엔지니어링 파이프라인을 최적화하는 데 필수적입니다.
HDD 성능을 좌우하는 두 가지 핵심 시간
하드 디스크에서 데이터를 읽거나 쓰는 데 걸리는 시간은 크게 세 가지 요소로 구성됩니다. 그중에서도 탐색 시간(Seek Time)과 회전 지연 시간(Rotational Latency)이 성능에 가장 큰 영향을 미칩니다.
탐색 시간(Seek Time): 헤드의 움직임
탐색 시간은 데이터를 읽거나 쓸 헤드(Read/Write Head)가 원하는 데이터가 저장된 트랙(Track)으로 이동하는 데 걸리는 시간입니다. 하드 디스크 내부에서 헤드가 물리적으로 움직여야 하기 때문에, 이 시간은 상당히 길게 소요될 수 있습니다.
회전 지연 시간(Rotational Latency): 플래터의 회전
회전 지연 시간은 헤드가 원하는 트랙에 도달한 후, 해당 트랙에서 실제로 원하는 데이터 섹터(Sector)가 헤드 아래로 회전하여 올 때까지 기다리는 시간입니다. 플래터(Platter)가 회전하기를 기다려야 하므로 발생하는 지연 시간입니다.
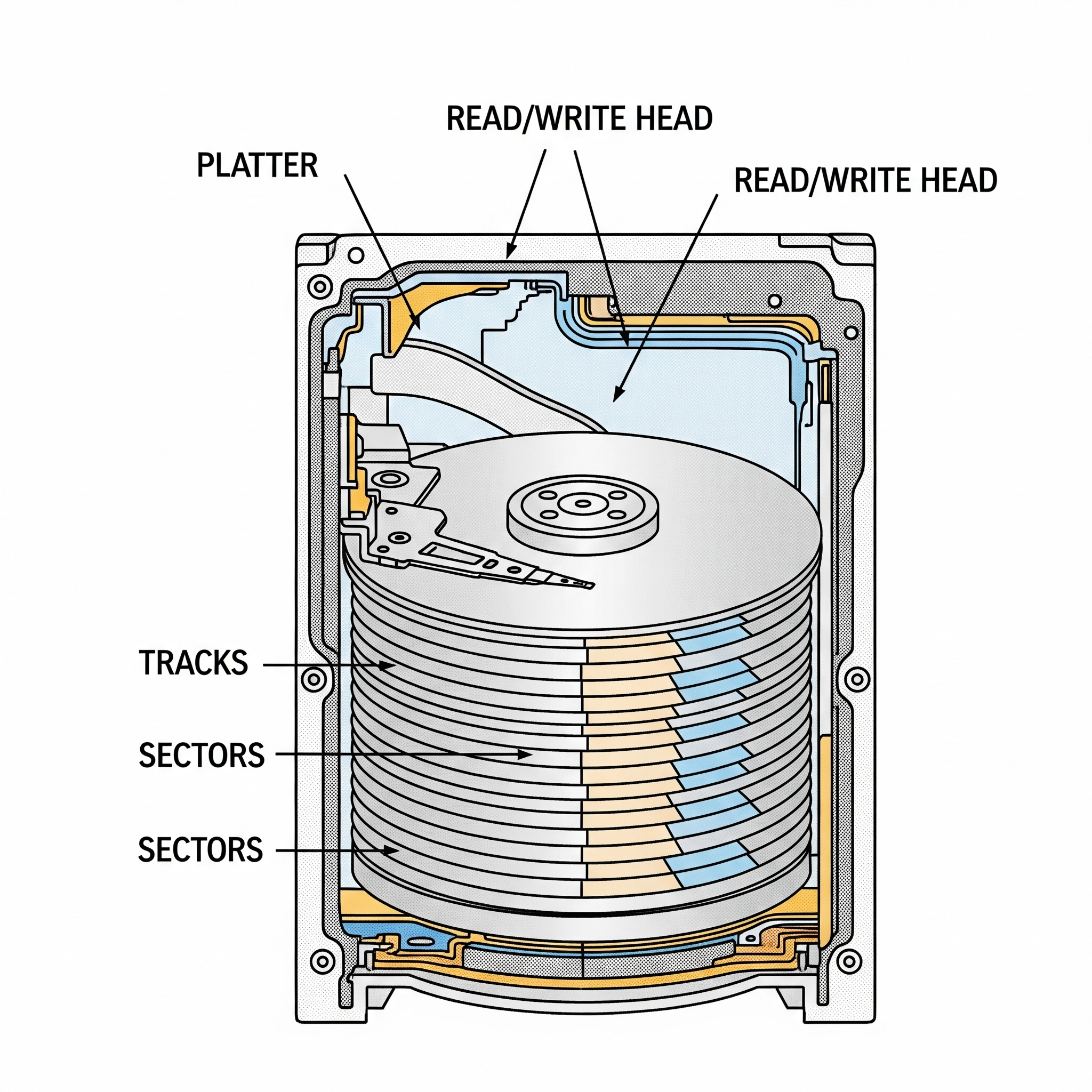
랜덤 액세스(Random Access): 느린 이유 파헤치기
랜덤 액세스는 디스크의 여러 곳에 흩어져 있는 데이터를 불규칙적인 순서로 읽거나 쓰는 것을 의미합니다. 마치 책장에서 필요한 책을 무작위로 여기저기서 뽑는 것과 같습니다.
이 방식의 가장 큰 문제는 데이터 블록 하나당 매번 탐색 시간과 회전 지연 시간이 크게 발생한다는 점입니다. 데이터를 읽을 때마다 헤드가 새로운 트랙으로 움직여야 하고, 원하는 섹터가 돌아오기를 기다려야 하기 때문입니다. 이 과정이 반복되면서 전체 디스크 접근 시간이 매우 길어집니다.
순차 액세스(Sequential Access): 압도적으로 빠른 비결!
반면 순차 액세스는 디스크에 물리적으로 인접하게 저장된 데이터를 순서대로 읽거나 쓰는 것을 의미합니다. 마치 책장에서 순서대로 책을 뽑아내는 것과 비슷하죠.
순차 액세스가 빠른 핵심 비결은 다음 두 가지입니다:
- 탐색 시간 최소화: 한 번 헤드가 특정 트랙에 위치하면, 다음 데이터 블록은 대부분 동일 트랙이나 바로 옆 트랙에 존재합니다. 따라서 헤드의 움직임이 거의 없거나 짧아 회전 지연 시간도 줄어듭니다.
- 회전 지연 시간 최소화: 데이터가 순서대로 배치되어 있어, 한 섹터를 읽고 나면 다음 섹터가 거의 즉시 헤드 아래로 회전하여 옵니다. 덕분에 데이터를 물 흐르듯이 연속적으로 읽을 수 있어
이러한 이유로 순차 액세스는 랜덤 액세스보다 훨씬 효율적이고 빠르게 데이터를 읽고 쓸 수 있습니다.
데이터 엔지니어 관점에서 본 디스크 접근 시간 최적화
데이터 엔지니어라면 이러한 하드 디스크의 특성을 이해하는 것이 매우 중요합니다. 대규모 데이터 처리 시스템을 설계할 때 디스크 접근 시간을 최소화하는 전략은 성능 향상에 직결됩니다.
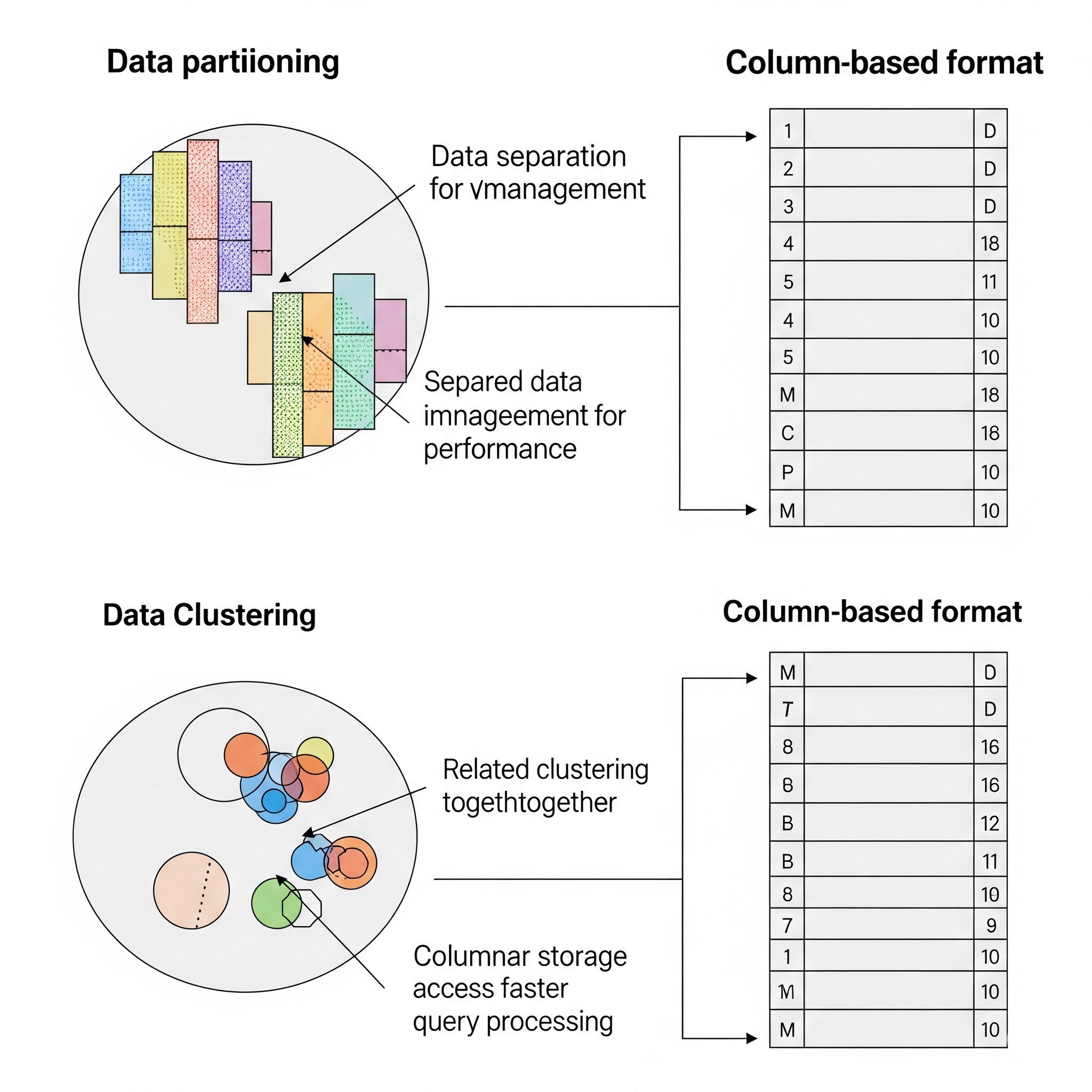
데이터 배치 최적화: 파티셔닝과 클러스터링
자주 함께 사용되는 데이터를 디스크의 물리적으로 가까운 곳에 배치하면
순차 액세스를 유도하여 쿼리 성능을 크게 높일 수 있습니다. 예를 들어, 데이터 웨어하우스나 데이터 레이크를 설계할 때 파티셔닝(Partitioning)이나 클러스터링(Clustering) 같은 기법을 사용하면 유사한 데이터를 묶어 저장하여 디스크 접근 시간을 줄일 수 있습니다.
컬럼 기반 파일 포맷 선택: Parquet, ORC
Parquet이나 ORC와 같은 컬럼 기반 파일 포맷은 데이터를 컬럼별로 묶어 저장합니다. 이는 특정 컬럼에 대한 쿼리 시, 필요한 데이터만 효율적으로 순차 읽기할 수 있도록 도와주므로 대용량 데이터 분석에 특히 유리합니다.
스트리밍 처리 고려: Kafka, Flink, Spark Streaming
Apache Kafka와 같은 메시지 큐 시스템이나 Apache Flink, Spark Streaming과 같은 스트리밍 처리 프레임워크는 데이터를 연속적으로, 즉 순차적으로 처리하는 데 최적화되어 있습니다. 이는 하드 디스크의 순차 액세스 효율성과도 맥락을 같이 하므로, 대용량 실시간 데이터 처리에 적합합니다.
SSD의 등장과 디스크 접근 시간의 변화
최근에는 SSD(Solid State Drive)가 보편화되면서 디스크 접근 시간의 양상도 변화하고 있습니다.
SSD는 하드 디스크(HDD)와 달리 물리적인 헤드의 움직임이나 플래터의 회전이 없으므로, 탐색 시간과 회전 지연 시간이 거의 발생하지 않습니다.
따라서 SSD에서는 랜덤 액세스와 순차 액세스의 성능 차이가 HDD만큼 크지는 않습니다. 하지만 여전히 데이터 블록 단위 읽기/쓰기 및 내부 컨트롤러의 효율성 때문에 순차 액세스가 여전히 유리한 경우가 많습니다.
데이터 엔지니어는 시스템 요구 사항과 예산을 고려하여 저장 장치를 선택할 때 이러한 특성을 반드시 고려해야 합니다.

백엔드 개발자를 위한 핵심: 디스크 접근 시간, 이것만 기억하세요!
하드 디스크의 물리적인 특성상 탐색 시간과 회전 지연 시간이 랜덤 액세스 성능에 큰 영향을 미칩니다. 따라서 백엔드 개발자나 데이터 엔지니어는 이 점을 고려하여 데이터를 어떻게 저장하고, 어떤 순서로 처리할지 전략을 수립해야 합니다.
오늘 배운 디스크 접근 시간의 개념과 랜덤 액세스, 순차 액세스의 차이를 이해한다면, 더욱 효율적이고 성능 좋은 시스템을 구축하는 데 큰 도움이 될 것입니다. 궁금한 점이 있다면 더 깊이 탐구하며 기술 역량을 키워나가시길 바랍니다!
'개발' 카테고리의 다른 글
| PostgreSQL 보안의 핵심: pg_hba.conf 파일 완벽 이해하기! (2) | 2025.07.24 |
|---|---|
| Airflow 마스터하기: CeleryExecutor와 Redis로 분산 작업 실행! (31) | 2025.07.24 |
| Docker 이미지 캐싱: Google Cloud Build에서 빌드 속도 높이기! (0) | 2025.07.24 |
| OLAP의 비밀: 컬럼 기반 저장으로 빅데이터 분석을 빠르게! (0) | 2025.07.23 |
| IP 주소의 모든 것: 사설 IP (private), 공인 IP (public), CIDR 완벽 이해 가이드 (1) | 2025.07.23 |



